Lorna Balkan
1 Introduction
This report describes how we applied the automatic indexing tool, KEA (see Witten et al. (2005)) to some of the UK Data Archive’s document collections, provided through the UK Data Service, and how we evaluated the results. Our aims were (1) to see whether Kea could potentially be used in the future at the Archive to aid metadata creation and (2) to develop recommendations for the future use of automatic indexing with an existing thesaurus.
Specifically, we sought to answer the following questions:
- How well does KEA perform (compared to the gold standard) across a variety of corpora, where these corpora differ with respect to:
- genre
- topic
- total corpus size
- document length
- indexing type (in terms of number and level)
- Why is Kea more successful on some document collections than others?
The experiment also revealed ways in which the thesaurus, HASSET, and Archive-internal metadata processes could be improved.
2 Evaluation tools and data
2.1 The document collection
Our initial intention was to use KEA to index the following document collections:
- The Nesstar bank of variables/questions
- Survey Question Bank (SQB) questionnaires
- ESDS data catalogue records
- abstracts (from all catalogue records)
- full catalogue records (from Study Number 5000 onwards: these are the most recent catalogue records, dating from 2005)
- Other full-text documents:
- case studies
- support guides
Corpus (3) was conflated into one corpus, consisting of all partial catalogue records. This happened because some studies did not have any abstracts, so basing the indexing on abstracts alone was not useful. The full catalogue record contained too many fields that were producing unhelpful index terms, so it was decided to use partial records only, consisting of the following fields:
- Title
- Alternative title
- Series title
- Abstract
- Geographical units
- Observation units
For the purposes of training KEA, all corpora needed to have manual indexes. Collections (2) and (3) had been previously indexed (but note that in Corpus (2) the number of manual index terms was restricted by the size of the PDF’s ‘document properties’ box, and in Corpus (3) manual indexing is based on full documentation, rather than the abstracts). Collection (4) had been indexed at subject category level. During the project, a mapping was defined between the subject categories and HASSET, and these HASSET terms then assigned to this collection (note that these terms are generally high level terms). Collection (1) was manually indexed especially for the project. See Barbalet (2013) for a fuller discussion of the manual indexing.
These four corpora differ in terms of:
- genre
- topic
- total corpus size
- document length
- indexing type (in terms of number and level)
- average number of manual keywords assigned per document
Note that, although corpus (4) consists of different types of document (user guides and case studies), because there were relatively few documents of each type, they were considered to be one corpus as far as training KEA was concerned.
Each document collection was divided into a training dataset (80% of the total number of documents in the collection), and a test dataset (the remaining 20%). KEA was trained on each training dataset separately, and evaluation results reported for that test dataset. Fifty documents from each test dataset were selected at random for manual evaluation (see Section 4 below).
2.2 HASSET
HASSET has been described in a previous blog (see Balkan and El Haj (2012)). For the purposes of the evaluation experiment, geographical terms were removed, since they produced too many incorrect index terms.
2.3 Description of KEA
El Haj (2012) has described in detail how KEA works. It is a term extraction system which includes a machine learning component. The algorithm works in two main steps:
(1) candidate term identification, which identifies candidate phrases (n-grams) from the text and maps these to thesaurus terms (in our case, HASSET). Candidate terms that are synonyms of preferred terms are mapped to their preferred terms.
(2) filtering, which uses a learned model (using training data labelled with thesaurus terms) to identify the most significant keywords based on certain properties or “features” which includes the tf.idf measure, the position of the first occurrence of a keyword in a document, the length of keywords and node degree (the number of keywords that are semantically related to a candidate keyword).
KEA was applied to three corpora (Nesstar questions/variables, SQB questionnaires and case studies/support guides) in stemming mode. The model was then rerun in non-stemming mode on the catalogue records.
For three corpora (SQB questionnaires, catalogue records and case studies/support guides) the system was set to produce up to 30 KEA keywords. For Nesstar, a maximum of 10 KEA keywords were generated, due to the small amount of text and the correspondingly few keywords that had been manually assigned.
3 Evaluation methodology
3.1 Overview
To judge the system’s performance, two types of evaluation were carried out:
In the automatic evaluation, KEA-generated keywords were compared with the set of manually assigned keywords (the so-called ‘gold standard’). In addition, a manual evaluation was performed on a subset (50 documents) of the test set, which involved comparing the KEA keywords to the texts they have been used to index (see Section 4 below). The manual evaluation also sought to discover why KEA either failed to find concepts that had been assigned manually (so-called ‘silence’) or suggested incorrect terms (so-called ‘noise’) (see Section 7 below).
3.2 Evaluation metrics
The main evaluation metrics we used were precision, recall and F1-score, defined as follows:
· Precision = 
· Recall = 
· F1-score = 2 * 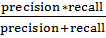
For the automatic evaluation, we define a KEA keyword to be ‘relevant’ if it is an exact match with a manual keyword. In manual evaluation, evaluators can judge a keyword to be relevant, even if it is not an exact match (see Section 4.3 below).
Precision, recall, and F1-scores were calculated on a document level, then aggregated over each document collection. We used an example-based, as opposed to a label-based approach for our aggregation scores (see Santos et al. (2011) and Madjarov et al. (2012)). The example-based approach sums the evaluation scores for each example (or document) and divides them by the total number of examples, while the label-based approach computes the evaluation score for each label (or keyword) separately and then averages the performance over all labels. Label-based evaluation includes micro-precision, macro-precision, etc. Given the large amount of keywords in our collection (potentially, the whole of HASSET), the example-based approach was preferred.
Formally, example-based precision, recall are calculated as follows (see Santos et al. (2011)):
Precision = 
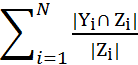
Recall = 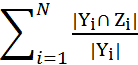
where N is the number of examples in the evaluation set, Yiis the set of relevant keywords, and Zi is the set of machine generated keywords.
We calculated the Average F1 score by summing the F1 scores of all the documents and dividing by the number of documents.
4 Manual evaluation
4.1 Overview
In the automatic evaluation KEA-generated keywords were compared with the manually assigned keywords only. In the manual evaluation, evaluators were asked to judge how relevant the automatically-generated keywords were to the text to which they referred. Evaluators could also record, as secondary information, reasons for lack of relevance, and how close the KEA terms were to the set of manual keywords semantically – see Section 4.3 below.
4.2 Evaluators
Two evaluators were assigned to the evaluation task. Evaluator (1), who is an expert indexer, evaluated each corpus (except the user guide/case study corpus) for relevance; evaluator (2) evaluated the user guide/case study corpus for relevance and assigned relatedness scores to the corpora (see 4.3 below). Both evaluators have many years’ experience of working at the UK Data Archive, and have a thorough knowledge of HASSET.
4.3 Stages and protocol
Manual evaluation was performed in two separate stages. First, the evaluator was presented with an evaluation form (see Appendix 5) and asked to read the original text to judge the relevance (or suitability) of each KEA keyword, on a 3-point scale:
How suitable is the KEA term for Information Retrieval?
5. Extremely suitable = should definitely be keyword
2. Partially suitable = redundant[1], or somewhat too narrow or too broad
0. Unsuitable = far too broad, or completely wrong
These scores were used to derive Precision, Recall and F1 scores for the corpora (see Section 3.2 above). The definition of relevance/suitability in our experiment depends on the type of evaluation, as follows:
- Automatic evaluation: the KEA keyword is considered relevant only if it is an exact match of a manual keyword
- Manual evaluation:
- ‘strictly relevant’: the KEA keyword is considered relevant if it is either an exact match of a manual keyword, or rated ’extremely suitable’ by the evaluator
- ‘broadly relevant’: the KEA keyword is considered relevant if it is either an exact match of a manual keyword, or rated either ‘extremely suitable’ or ‘partially suitable’ by the evaluator.
In the evaluation form presented to the evaluator, the manual keywords are shown in alphabetical order, next to the KEA keywords that appear in the order in which they are ranked by KEA. It is assumed that all exact matches are ‘extremely suitable’, since they have been assigned by professional indexers, so the form is pre-filled to reflect this.
Evaluators were also asked, for keywords that are either ‘partially suitable’ or ‘unsuitable’, to provide the following information:
Reason for lack of suitability of Kea term:
- Too broad
- Too narrow
- Redundant = concept already covered by other terms (that form an associative relationship) in the KEA set
- Completely wrong
This information is used for the informal error analysis we performed (see Section 7). (Note that it was initially assumed that all redundant terms would be partially suitable, but in the event some were judged to be unsuitable.)
A second stage of evaluation, which was carried out independently of the first stage, sought to establish how closely related the KEA keywords are to the manual keywords, according to the following scale and criteria:
To what extent is the KEA term semantically related to the Gold standard?
5. Totally related (exact match)
4. Closely related: NT, BT or RT to manual keyword
3. Somewhat related: in the same hierarchy as manual keyword
2. Remotely related: related, but not in the same hierarchy as manual keyword
1. Unrelated
The first category (‘exact match’) is computed automatically and pre-filled in the evaluation form[2]. Note that relatedness scores were not calculated for the catalogue record corpus, due to time constraints.
5 Comparison with other approaches
The standard evaluation paradigm for automatic indexing is to automatically compare machine-generated indexes with a gold standard. The problems with this approach are well documented, since the choice of index terms is often very subjective[3]. Approaches to overcoming this problem include pooling the set of index terms suggested by a number of different indexers, and taking either that or their intersection as the gold standard (see for example Pouliquen et al. (2003)). Another common approach is to accept not just exact matches as relevant terms, but those terms that are semantically related to the manual keywords. Semantic relatedness to the manual keywords can be computed automatically based on various criteria, for example closeness of the terms in the thesaurus hierarchy (see for example Medelyan and Witten (2005) and/or morphological similarity (for example Zesch, T. and Gurevych, I. (2009).
A problem with these approaches is that they assume that the closer the match to the gold standard semantically, the more relevant a term will be as a keyword. However, we show (in Section 8.4 below) that this assumption is not always true, as in some of our corpora, some relevant keywords were totally unrelated to those in the gold standard for reasons discussed in Section 2.1 above.
The alternative to automatic evaluation is to perform a manual evaluation. However, this is both costly and time-consuming. In a manual evaluation, evaluators are most often asked to compare the set of machine-generated keywords directly with the source text (see for example Jacquemin et al. (2002), Névéol et al. (2004) and Medline (2002)). While this is a useful approach, it does not capture any relationship between what the machine assigns and what the human assigns as keywords, which may be useful to know.
Our approach aims to capture both relatedness to the gold standard and relevance to the source text.
Many manual evaluations also involve a qualitative analysis of the automatic indexing terms (see for example Abdul and Khoo (1989), Eckert et al. (2008), Clements, and Medline (2002). We also undertook an error analysis of our results (see Section 7).
6 Limitations of the approach
Our experiment suffered from a number of limitations, due mainly to time constraints:
- Gold standard:
- Taking the set of manually assigned keywords as the gold standard is particularly problematic for the following datasets:
- Catalogue records: manual keywords and KEA keywords have not been used to index the same thing – the manual indexers have indexed the whole documentation, while KEA has been used to index partial catalogue records only, including the abstract. The abstract is, however, often taken from the documentation and is a summary of it.
- SQB questionnaires: due to space restrictions (see Section 2.1 above) existing manual keywords have been limited in number.
- Case studies/user guides: a small subset of the thesaurus (mapped from subject categories) has been used for manual indexing, while KEA used the whole thesaurus.
- The number of keywords in the gold standard does not always match the number of keywords generated by KEA. Where there are more manually-generated keywords than KEA keywords, 100% recall will not be possible. Several researchers have suggested recalculating evaluation scores for different numbers of automatic keywords (e.g. 5, 10, 20) or using a ‘dynamic rank’, i.e. where the number of manually assigned keywords is the same as the number of automatically assigned keywords (see for example Steinberger et al. (2012)). As Steinberger et al. point out, however, this is not helpful for new texts which have no manual terms as a reference.
- Number of evaluators:Due to time and resource restrictions, only one evaluator was used to evaluate each document – ideally, a number of evaluators would evaluate each document and results averaged across them.
- Indexer-centred evaluation:This evaluation is very much indexer-centred, since it is designed to investigate whether or not KEA could be a useful tool for indexers. To get a proper estimate of its value to users, a user-centred evaluation would need to be conducted.
- Evaluation form:A blind evaluation, where the evaluator is unaware whether the keyword has been generated manually or automatically, would make the evaluation less subjective.
7 Error analysis
We distinguish between precision errors, where KEA returns incorrect or partially relevant terms, and recall errors, where KEA fails to find relevant terms.
7.1 Precision errors
Reasons for poor precision include cases where the KEA keyword was:
- too broad
E.g. EMPLOYMENT for when the text is about “STUDENT EMPLOYMENT”
This includes cases where the keyword is chiefly used as a placeholder in HASSET, with a scope note advising the use of a more specific term instead:
E.g. RESOURCES has the following scope note: “AVAILABLE MEANS OR ASSETS, INCLUDING SOURCES OF ASSISTANCE, SUPPLY, OR SUPPORT (NOTE: USE A MORE SPECIFIC TERM IF POSSIBLE). (ERIC)”)
- too narrow
This generally only occurred in the case study/support guide corpus.
- redundant
E.g. CHILDBIRTH when PREMATURE BIRTHS is also found
- somewhat or completely wrong
Category (4) can be for a variety of reasons, including:
- KEA identifies the correct term, but it has a different meaning in HASSET to that in the text because:
- they are homonyms:
E.g. KEA retrieves the keyword WINDOWS (meaning features of a house) because it matches “Windows” (Computer software) in the text
- the term is used idiomatically in the text, but has a literal meaning in HASSET[4]
E.g. PRICES is used in its literal sense in HASSET, but idiomatically in the text – “Do higher wages come at a price?”
- the HASSET term is used in a restricted sense (often indicated in a scope note) which is different to the general language usage found in the text
E.g. the HASSET term WORKPLACE is used to refer to the location of work only
- KEA identifies the wrong term because:
- it fails to distinguish between terms containing qualifiers
E.g. KEA retrieves CHILDBIRTH (UF: “LABOUR (PREGNANCY)”) instead of ” LABOUR (WORK)” because it matches “labour” (meaning ‘work’) in the text
- it is unable to parse a compound term correctly:
E.g. KEA retrieves DEVELOPMENT POLICY because “collections development policy” was found in the text (i.e. it matches an incorrect sub-part of the compound term)
- the errors are due to stemming:
E.g. NATIONALISM matches “nation” in the text
E.g. TRUST matches “trusts” in the text
E.g. ORDINATION matches “co-ordination” in the text
- Too many closely related terms in HASSET make it difficult for KEA to discriminate between them. Examples include:
- the many variants of TRAINING in the thesaurus – FURTHER TRAINING, OCCUPATIONAL TRAINING, EMPLOYER-SPONSORED TRAINING
- OFFSPRING and CHILDREN: OFFSPRING has the scope note: USE SPECIFICALLY FOR CHILDREN, REGARDLESS OF AGE. NOT TO BE USED AS AN AGE IDENTIFIER. MAY BE USED FOR ADULT CHILDREN, OR FOR QUESTIONS WHERE AGE OF CHILD IS NOT SPECIFIED. TERM CREATED JUNE 2005. PREVIOUSLY THE TERM “CHILDREN” MAY HAVE BEEN USED.
- CRIMES is a UF of OFFENCES, not CRIME, which is a separate term
- The term belongs to a part of the document that should be ignored for indexing purposes (e.g. author names in case studies). Note that KEA gives greater weight to terms the closer they occur to the beginning of the document. This causes a problem in some corpora, e.g. user guides and case studies, which often begin with background text to set the topic in context.
Possible solutions for precision errors:
- Add terms to stopwords:
E.g. INFORMATION, DATA, RESEARCH, ANALYSIS, EVALUATION, TESTS
- Add new UFs to preferred terms
- Reduce stemming[5]
- Remove irrelevant parts of the text:
This would be relatively easy to do for some of our corpora, e.g. case studies
- Apply word sense disambiguation (WSD) techniques to help identify the correct use of a homonym in HASSET:
There is some form of context sensitivity in KEA, since the filtering stage (see Section 2.3 above) is based partly on the node degree (the number of keywords that are semantically related to a candidate keyword). Other ways of introducing context sensitivity have been discussed in the literature – see for example Pouliquen et al. (2003) who use the notion of associate terms to help select keywords.
7.2 Recall errors
Reasons for poor recall include:
- The concept is in HASSET, but is not recognised by KEA
- The concept is not in HASSET so has to be represented by a combination of other terms. Examples include:
- CHILDHOOD POVERTY is represented by SOCIALLY DISADVANTAGED CHILDREN
- some methodological terms
Sources of recall errors include:
- The HASSET term has a slightly different form from that found in the text:E.g. PRICE POLICY is not found although “pricing policy” is in text
- The HASSET term is hyphenated, while the term in the text is not:E.g. BREAST-FEEDING not found although “breastfeeding” is in text
- the HASSET term is too abstract to be found verbatim in the textE.g. LIFE SATISFACTION is not found, although “enjoying life” is in text
In many cases, the source of recall errors is not obvious, and needs further investigation.
Possible solutions for recall errors include:
- Add new UFs to current HASSET terms
- Add new preferred terms
- Add stemming
8 Discussion of the results
8.1 General remarks
The following subsections summarise the results of the evaluation as shown in the appendices below. The results are all based on 50 samples of each test set. It should be borne in mind that the catalogue record results were produced using a different model of KEA, and unlike the other corpora, KEA indexing was based on a subset of the text that was used for the manual indexing, as explained in Section 2.1 above. For this reason, the results are not directly comparable with those of the other corpora. 8.2 Precision, recall and F1
Performance was measured in terms of Precision, Recall and F1. Three different degrees of each were recorded – Auto, Strict and Broad, as shown in Appendix 1:
- Auto: auto scores are based on exact matches between KEA and manual keywords. They can be computed automatically
- ‘Strict’: include exact matches and additional KEA keywords rated ’extremely suitable’ by the evaluator
- ‘Broad’: include exact matches, and additional KEA keywords rated either ‘extremely suitable‘ or ‘partially suitable’ by the evaluator.
Individually, the best performance overall was seen in the SQB corpus, with a broad F1 score of 0.43. Close behind are the Nesstar and case studies/support guide corpora, with c. 0.35 each. Catalogue records had a low F1 score of 0.21. This was to be expected, given that KEA had relatively little text to index from, compared to the manual indexers. This, together with the fact that KEA was applied in non-stemming mode, led to a poor recall score. However, the precision rate for catalogue records was 0.42, which means that the keywords KEA found are very often relevant.
The highest recall score was found in the case study/support guide corpus (0.73). This suggests that KEA could be usefully employed to suggest new relevant terms for this type of corpus.
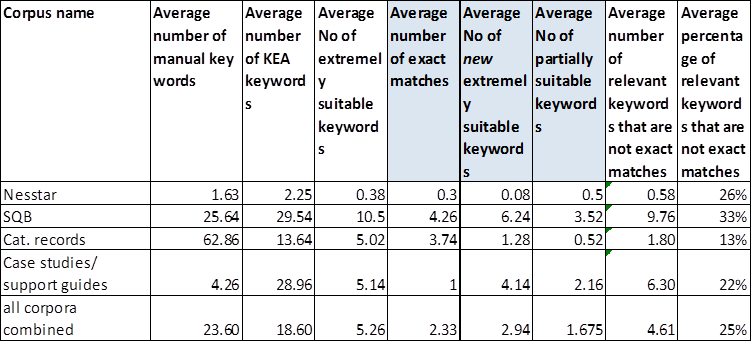
As expected there was relatively little overlap between KEA keywords and manual keywords (on average KEA found 18.60 keywords per document across the four corpora, of which only 2.33 were exact matches with the manual keywords) – see Appendix 4.2. However, a high percentage of KEA keywords were considered relevant/suitable even if they were not exact matches – 33% for the SQB corpus, with an average of 25% across all four corpora. This suggests that KEA could be a very useful tool for indexers.
It is not clear, from our initial experiments, to what extent the system’s performance is dependent on the number and size of training documents. Our four corpora differ considerably in this respect – the Nesstar collection contains the largest number of documents, but these are very small in size, containing a single question, while the SQB corpus contains the largest documents. The training datasets are 80% of the total number of documents in each corpus. If we assume that the training datasets are also 80% of the size of the entire corpora (which may not hold, since documents are not of a uniform length) then we can conclude that the highest F1 score is reported for the the corpus with the largest amount of training data (i.e. the SQB corpus as shown in Appendix 1) rather than that with the largest number of training documents (i.e. the Nesstar corpus). Performance is clearly related not just to the number and size of the training documents but to their associated keywords. The average number of manual keywords assigned per document varies considerably – in the sample shown in Appendix 4.2, the average number of manual keywords varies from 1.63 for Nesstar questions/variables to 62.86 for catalogue records – but it is important to bear in mind differences in the completeness and level of the keywords, as well as their number.
Further investigation is also required to establish the influence of genre on performance. For example, the case studies and support guide collections were considered to be a single corpus for the sake of the experiment, but may exhibit different behaviour if processed and evaluated separately. The support guides, for instance, use more formal language than the case studies, which are aimed at a popular audience, so are unlikely to cause precision errors due to the idiomatic use of language.
Within text types, topic clearly plays a role. For example, support guides on methodology and cataloguing procedures fared less well than the guides on substantive topics like health and employment, since HASSET has few terms to cover the first topics.[6]
8.3 Reasons for partial or lack of suitability of keywords
For three out of the four corpora (Nesstar, SQB and catalogue records), those terms which are deemed to be partially suitable, instead of extremely suitable were too broad (see Appendix 2). Only in the case of case studies/support guides, were a sizeable proportion of partially suitable keywords (c.50%) deemed to be too narrow.
Across all four corpora unsuitable terms were usually judged to be completely wrong, rather than too broad.[7]
8.4 Relatedness scores
Relatedness measures how close the KEA keywords are to the manual keywords.
Across the three corpora that we rated for relatedness (Nesstar, SQB and case studies/support guides), there is no consistent relationship between the suitability of KEA keywords and their relatedness to the manual keywords. In the case of Nesstar, 100% of keywords that were not exact matches of the manual keywords but deemed ‘extremely suitable’ were either closely or somewhat related to the manual keywords, while with the SQB and case studies/support guides over 50% were either remotely or unrelated to the manual keywords (see Appendix 3).
This suggests that, in the absence of manual evaluation, relatedness of KEA keywords to manual keywords based on their position in the thesaurus could not be used as a good indicator of whether or not they are extremely relevant. A similar situation is true for partially suitable keywords and their relationship with manual keywords.
There could be several reasons for this. First, the manual keywords may exclude important topics, due to time or space limitations (this is particularly true for the SQB and the case study/support guide corpora). Alternatively, or additionally, the KEA keywords may well be closely related to the manual keywords, but this is not reflected in the thesaurus structure, upon which the relatedness definitions are based. An example is VOTING, which was is not related to VOTING BEHAVIOUR or VOTING INTENTION in the thesaurus. Examination of cases such as these will be useful when we come to revise the thesaurus.
Conversely, some KEA keywords rated as ‘somewhat related’ because they share the same hierarchy as a manual keyword, are in fact semantically far distant. For example, SUGAR is in the same hierarchy as MEDICAL DRUGS and is thus judged to be somewhat related. This is because their shared hierarchy PRODUCTS is very large.
9 Conclusions and recommendations
Our experiments with KEA proved a useful introduction to automatic indexing at the UK Data Archive. The results of our initial investigations are encouraging, and lead us to believe that KEA could provide a useful tool to our indexers. We would however have to conduct user-oriented evaluation to see how the system could be incorporated into our work-flows.
It would also be useful to conduct further experiments with the system to see how we could improve the model and run the system more efficiently (see some of the suggestions we make in Section 7).
Work on KEA has also provided us with useful insights into how we could improve our processing procedures (which we reviewed when we prepared the texts and metadata prior to running KEA) and the thesaurus – for example, our preliminary error analysis highlighted the need for more synonyms and revealed cases where there are too many similar terms.
We make the following recommendations:
- KEA is a useful tool for indexers of full text social science materials;
- however, KEA would work best as a suggester of new terms, with moderation from a human indexer;
- KEA could also be used as a quality assurance tool, to ensure that terms are not overlooked – some terms it suggested that were highly relevant had not been included in the gold standard, manual indexing;
- more work is needed to investigate KEA further and to see how it could be incorporated technically, and in terms of process, into ingest systems.
Notes
1. See Barbalet (2013) for a more detailed discussion of redundancy in indexing.
2. Note that the calculation of categories ‘closely related’ and ‘somewhat related’ could also be automated, and this may be implemented at a future date.
3. Indexing of our corpora follows quality control procedures which helps address the problem of subjectivity – see Barbalet (2013).
4. Cases like these were only found in the case studies/user guides corpus.
5. Note, however, that while reducing stemming will improve precision, it will have a negative impact on recall, and there is always a trade-off between precision and recall.
6. It turned out also that the Nesstar training dataset contained many duplicated questions, unlike the test sample, which had very few, and this may have had an effect on the results.
7. Note: there were also some cases of terms being unsuitable because they were too narrow, or redundant – neither of these possibilities were envisaged when the experiment was set up, so statistics for these are not reported separately. See Barbalet (2013) for possible reasons for these error types.
References
Abdul, H. and Khoo, C. (1989) ‘Automatic indexing for medical literature using phrase matching – an exploratory study’, In Health Information: New Directions: Proceedings of the Joint Conference of the Health Libraries Sections of the Australian Library and Information Association and New Zealand Library Association, Auckland, New Zealand. 12-16 November 1989, pp. 164-172.
Balkan, L. and El Haj (2012): SKOS-HASSET evaluation plan, blog.
https://hassetukda.wordpress.com/2012/08/16/skos-hasset-evaluation-plan/
Barbalet, S. (2013) Gold standard indexes for SKOS-HASSET evaluation: a review, blog. https://hassetukda.wordpress.com/
Clements, J. ‘An Evaluation of Automatically Assigned Subject Metadata using AgroTagger and HIVE’ http://aims.fao.org/sites/default/files/files/Clements_FAO_Metadata_Assignment.pdf
Eckert, K., Stucken-Schmidt, H. and Pfeffer, M. (2008): Interactive thesaurus assessment for automatic document annotation, in Proceedings of the Fourth International Conference on knowledge capture (k-cap 2007), Whistler, Canada. http://publications.wim.uni-mannheim.de/informatik/lski/Eckert07Thesaurus.pdf
El Haj, M. (2012) UKDA Keyword Indexing with a SKOS Version of HASSET Thesaurus, blog. https://hassetukda.wordpress.com/2012/09/24/ukda-keyword-indexing-with-a-skos-version-of-hasset-thesaurus/
Jacquemin, C., Daille, B., Royaute, J. and Polanco, X (2002): ‘In vitro evaluation of a program for machine-aided indexing’, Information Processing and Management, 38(6): pp. 765-792, http://perso.limsi.fr/jacquemi/FTP/IPM-1354-jacquemin-et-al.pdf
Madjarov, G., Kocev, D., Gjorgjevikj, D. and Džeroski, S. (2012) ‘An extensive experimental comparison of methods for multi-label learning’, Pattern Recognition, doi:10.1016/j.patcog.2012.03.004, http://kt.ijs.si/DragiKocev/wikipage/lib/exe/fetch.php?media=2012pr_ml_comparison.pdf
Manning, C., Raghavan, P., and Schutze, H. Introduction to Information Retrieval (2008), Cambridge University Press, http://nlp.stanford.edu/IR-book/html/htmledition/evaluation-of-text-classification-1.html
Medleyan, O. and Witten, I. (2005) ‘Thesaurus-based index term extraction for agricultural documents, in: Proceedings of the 6th Agricultural Ontology Service (AOS) workshop at EFITA/WCCA 2005, Vila Real, Portugal. http://www.medelyan.com/files/efita05_index_term_extraction_agriculture.pdf
Medline (2002): A Medline indexing experiment using terms suggested by MTI: A report. http://ii.nlm.nih.gov/resources/ResultsEvaluationReport.pdf
Névéol, A., Soualmia, L.F., Douyère, M., Rogozan, A., Thirion, B. and Darmoni, S.J. (2004), ‘Using CISMeF MeSH ‘‘Encapsulated’’ terminology and a categorization algorithm for health resources, in International Journal of Medical Informatics, 73, pp. 57-54, Elsevier. http://mini.ncbi.nih.gov/CBBresearch/Fellows/Neveol/NeveolIJMI04.pdf
Pouliquen, B., Steinberger, R. and Ignat, C.(2003) ‘Automatic annotation of multilingual text collections with a conceptual thesaurus, Proceedings of the Workshop Ontologies and Information Extraction at EUROLAN 2003, http://arxiv.org/ftp/cs/papers/0609/0609059.pdf
Santos, A., Canuto, A. and Feitosa Neto, A. (2011) ‘A Comparative Analysis of Classification Methods to Multi-label Tasks in Different Application Domains’, Computer Information Systems and Industrial Management Applications, 3, pp.218-227, http://www.mirlabs.org/ijcisim/regular_papers_2011/Paper26.pdf
Spasic, I., Schober, D., Sansone, S-A., Rebholz-Schumann, D., Kell, D. and Paton, N. (2008) ‘Facilitating the development of controlled vocabularies for metabolomics technologies with text mining’, BMC Bioinformatics 2008, 9(Suppl 5):S5. http://www.biomedcentral.com/1471-2105/9/S5/S5
Steinberger, R., Ebrahim M., and Turchi, M. (2012) ‘JRC EuroVoc Indexer JEX – A freely available multi-label categorisation tool’, LREC conference proceedings 2012. http://www.lrec-conf.org/proceedings/lrec2012/pdf/875_Paper.pdf
Witten, I.H., Paynter, G.W., Frank, E, Gutwin, C. and Nevill-Manning, C.G. (2005) ‘Kea: Practical automatic keyphrase extraction’, in Y.-L. Theng and S. Foo (eds.) Design and Usability of Digital Libraries: Case Studies in the Asia Pacific, Information Science Publishing, London, pp. 129–152.
Zesch, T. and Gurevych, I. (2009) ‘Approximate Matching for Evaluating Keyphrase Extraction’, In Proceedings of the 7th International Conference on Recent Advances in Natural Language Processing September 2009, pp. 484-489, http://aclweb.org/anthology-new/R/R09/R09-1086.pdf
Appendix 1 Average Precision, Recall and F1 scores

Appendix 2 Reasons for partial or lack of suitability of keywords
2.1 Reasons for partial suitability of keywords
Average percentage per document of partially suitable keywords that are:
| Corpus name |
Too broad |
Too narrow |
Redundant |
| Nesstar |
85.00% |
5.00% |
10.00% |
| SQB |
64.85% |
19.61% |
12.35% |
| Cat. records |
84.38% |
0.00% |
12.50% |
| Case studies/ support guides |
50.69% |
49.31% |
0.00% |
2.2 Reasons for unsuitability of keywords
Average percentage per document of partially suitable keywords that are:
| Corpus name |
Too broad |
Completely wrong |
| Nesstar |
23.66% |
74.19% |
| SQB |
1.35% |
96.38% |
| Cat. records |
1.27% |
96.23% |
| Case studies/ support guides |
16.22% |
73.71% |
Appendix 3 Average relatedness scores
3.1 Average relatedness to manual keywords of extremely suitable keywords that are not exact matches
| Corpus name |
Closely related |
somewhat related |
remotely related |
unrelated |
| Nesstar |
50.00% |
50.00% |
0.00% |
0.00% |
| SQB |
31.33% |
17.71% |
11.35% |
41.63% |
| Cat. records |
|
|
|
|
| Case studies/ support guides |
25.19% |
14.29% |
15.85% |
44.63% |
3.2 Average relatedness to manual keywords of partially suitable keywords
| Corpus name |
Closely related |
somewhat related |
remotely related |
unrelated |
| Nesstar |
27.50% |
42.50% |
12.50% |
17.50% |
| SQB |
29.79% |
21.19% |
9.42% |
39.60% |
| Cat. records |
|
|
|
|
| Case studies/ support guides |
32.37% |
7.42% |
16.01% |
44.20% |
Appendix 4 Other statistics
4.1 Average relatedness and suitability
| Corpus name |
Average relatedness |
Average suitability |
| Nesstar |
2.12 |
1.26 |
| SQB |
2.29 |
2.01 |
| Cat. Records |
|
1.97 |
| Case studies/ support guides |
1.67 |
1.04 |
4.2 Average number of keywords (manual and Kea) per document

Appendix 5 Example of evaluation form